
Sikai Wang
Midterm_Summary
Project description: This project mainly focuses on applying what we need learned in python to come up with a solution to the current question. The process of this project includes getting 10K filings, reading and analyzing the downloads, and creating a informative report for that, which are ‘download_text_files.ipynb’, ‘build_sample.ipynb’, and ‘report.ipynb’.
1. Question
Do 10-K filings contain value-relevant information in the sentiment of the text?
2. Approach
import glob
import os
from time import sleep
import pandas as pd
from sec_edgar_downloader import Downloader
from tqdm import tqdm
import zipfile
import fnmatch
import warnings
warnings.filterwarnings("ignore", message="It looks like you're parsing an XML document using an HTML parser")
import fnmatch
import glob
import os
import re
from time import sleep
from zipfile import ZipFile
from datetime import datetime, timedelta
import requests
session = requests.Session()
from requests_html import HTMLSession
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
from near_regex import NEAR_regex # copy this file into the asgn folder
from tqdm import tqdm # progress bar on loops
from io import BytesIO
from zipfile import ZipFile
from urllib.request import urlopen
from scipy.stats import pearsonr
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
3. Findings
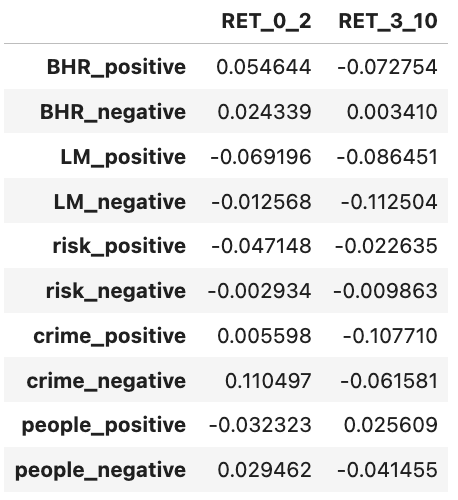
According to corr_df, I noticed that the relationship between LM and RET is negatively related. They get 4 negative correlation regardless of its version of return and side of LM. But for ML sentiment, it is almost the opposite. ML sentiment get 75% of its correlation positive. Especially for both negative side, they have completely the opposite outcome. But when we look at the magnitudes of the correlation, I find out that every correlation between sentiment and return is weak. There is no strong correlation even no natural correlation. It is not quite accurate to assure that if it is positive or negative, the return will be the one we want to see.
4. Discussion
I noticed that my comparison contradicts what Garcia, Hu, and Rohrer wrote in their ML paper. They found that the relationship between words and stock price even outperform their expectation. I believe what they mean is that there is moderately strong relationship between the word and stock price. There are four main reasons that may influence the result here. Firstly, they could use much more company than we did. Since S&P 500 only represent the top 500 firms. There are much more firms all over the world. The sample is too limited. Secondly, 2022 is the year right after pandemic year. Everything was not the same as before. World may changed since they may use the historical data, which is not that representative. Thirdly, the word number could also affect the result. Finally, it could also affect by the way I approached to this result. I may make some mistakes during the process although I think I tried my best to get correct.
For more details see GitHub Flavored Markdown.